Anthropic 今日正式发布了 Claude 系列最新旗舰模型 Claude Opus 4.8。新模型在编程可靠性、事实准确性以及复杂推理能力方面均有显著提升,同时在减少无依据结论方面取得了突破性进展。官方称这是 Claude 系列迄今最强大的模型。
Claude Opus 4.8 的编程能力尤为突出,在 SWE-Bench、HumanEval 等权威编程基准测试中的成绩均刷新纪录。Anthropic 表示,新模型在处理大型代码库时能更准确地理解上下文依赖关系,生成代码的错误率较前代降低了约 35%。
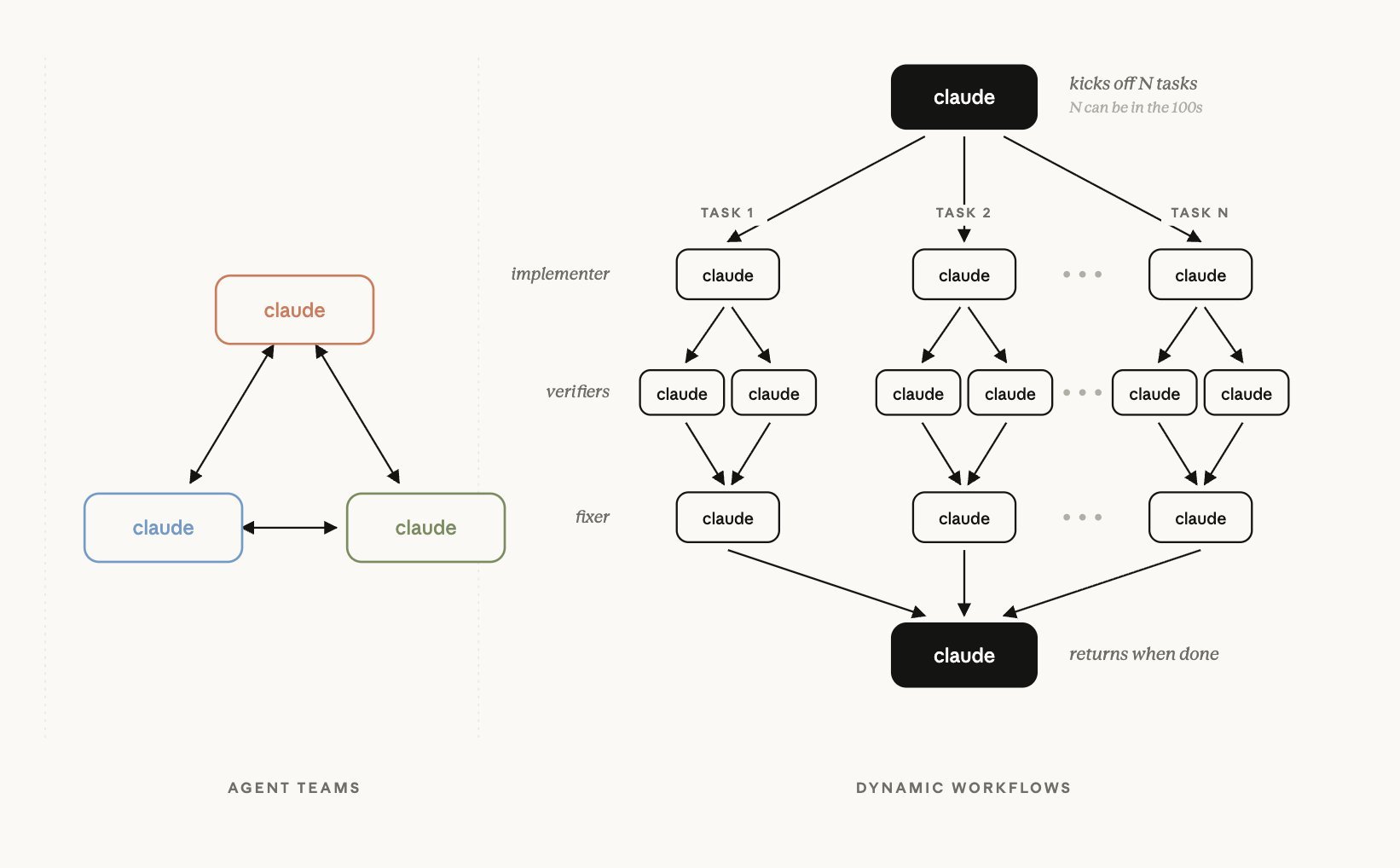
核心能力升级
Claude Opus 4.8 在多项核心指标上实现飞跃:长文本理解能力提升至 200K tokens 级别,多步推理准确率提升 28%,幻觉率降低至行业最低水平。模型还新增了结构化输出模式,可以严格按照用户指定的格式返回结果。
值得注意的是,Anthropic 还针对模型安全性进行了全面加强。Claude Opus 4.8 引入了动态置信度评估机制,模型在回答不确定的问题时会主动标注置信度等级,显著减少了无依据结论的产生。
争议与定价
然而,Claude Opus 4.8 上线当天就引发了争议——有用户发现该模型在自我认知测试中声称自己是千问和 DeepSeek 的训练产物,被质疑可能通过蒸馏技术学习了中国大模型。Anthropic 方面对此尚未作出正式回应。
API 定价方面,Claude Opus 4.8 输入价格 15 美元/百万 tokens,输出价格 75 美元/百万 tokens,相比 GPT-4o 略有优势。Anthropic 还宣布即将筹备近万亿美元估值规模的 IPO。

