2024年1月30日,科大讯飞发布了首个基于全国产化算力平台训练的全民开放大模型——讯飞星火V3.5,相比上一代模型在语言理解、文本生成、知识问答、逻辑推理、数学能力、代码能力和多模态能力等七个方面进行了全面升级。特别是在语言理解、数学能力方面已经超过 GPT-4 Turbo,进一步夯实了中国“最聪明”的大模型的地位。

在发布会现场,科大讯飞工作人员也展示了与讯飞星火V3.5的人机交互体验,它不仅能够清晰理解所说的含义,同时还能够实现多轮对话,完全感觉就是在“唠嗑”一般,并且还让讯飞星火V3.5有了一定的情绪感知,完全体会不到机器人的冰冷。
当主持人表达想要去哈尔滨旅行的想法后,讯飞星火V3.5快速为主持人定制了旅游攻略,还催促他赶快买票,因为此时正是春运时期,所有票都非常紧俏,这样的逻辑能力也是相当给力的。

所以在全程看完讯飞星火V3.5的发布会后,笔者就迫不及待的想要体验一下它的实力,并且将直观的与当下同样火爆的ChatGPT 最 新的 GPT-4、文心一言4.0几个大模型进行比较,重点从语言理解、数学能力、多模态、办公支持等多个维度来具体分析讯飞星火V3.5的真实表现。(注:目前除了讯飞星火V3.5外,其它两个对比大模型都是需要付费的)
语言理解
题目:大舅去二舅家找三舅说四舅被五舅骗去六舅家偷七舅放在八舅柜子里九舅借十舅发给十一舅工资的1000元。
问:1、究竟谁是小偷?2、钱本来是谁的?
其实这道题主要考验的是一个关系逻辑推理问题,我们看看几个大模型都是如何回答的。
讯飞星火V3.5
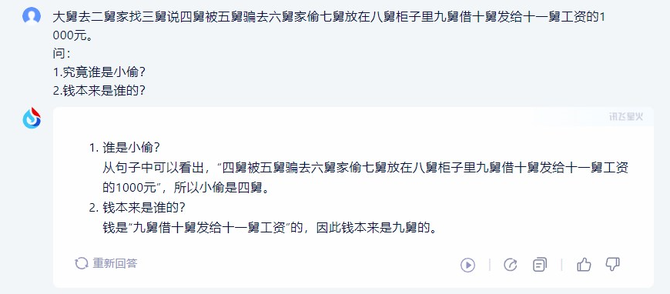
GPT-4

文心一言
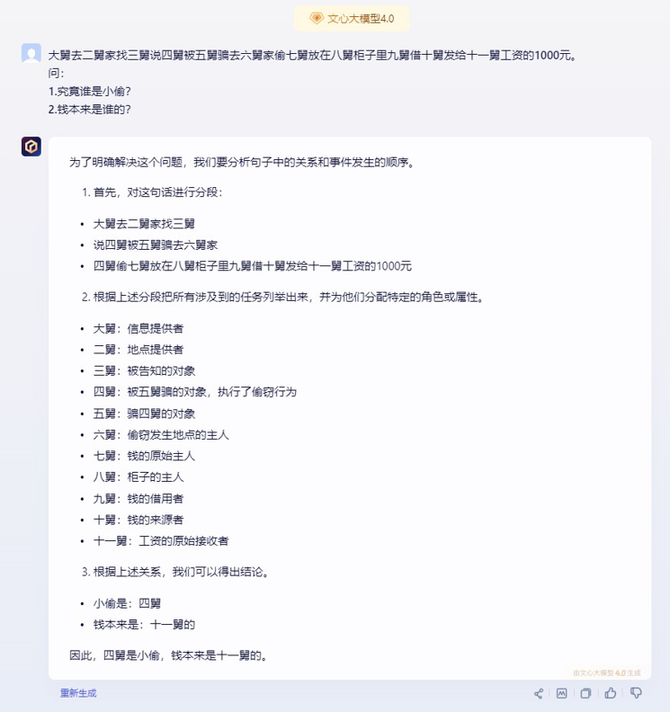
从对比中看出,目前各个大模型其实都是有一定逻辑推理能力的,但是在绕来绕去的文字里,只有讯飞星火V3.5给出了正确的结果,四舅偷了钱,钱是九舅的。而且讯飞星火V3.5的分析也是非常简洁明了,让用户很快就能明白其中关键缘由。
下面再出一道关于空间逻辑的题目。
题目:我是一名在校学生,图书馆在学校的中心位,实验楼在图书馆的南边,学生活动中心在学校的北边,教学楼和体育馆分别在学生活动中心的东边和西边,食堂在图书馆的东边,现在我在教学楼上完课需要去实验楼做实验,应该怎么走?
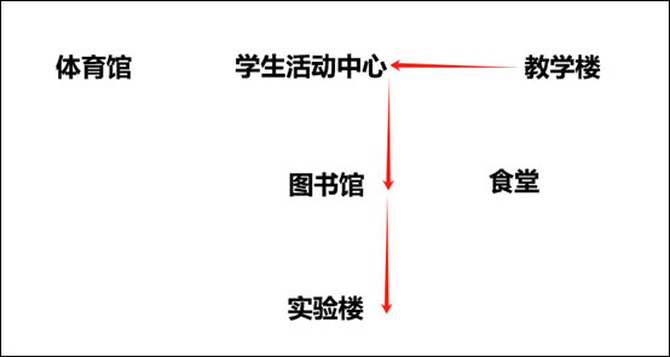
根据提示,笔者简单的画了一张草图,方便大家对照各个大模型的路线来判断对错。
讯飞星火V3.5
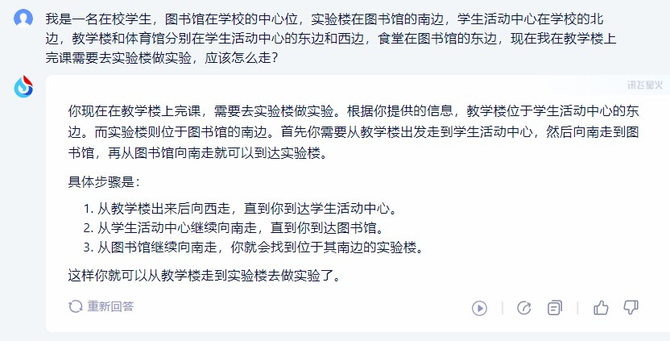
GPT-4

文心一言

对比之下,三个大模型的回答均是正确的,但是作为使用者,我更希望得到精简的答案,能够快速告诉我具体路线。所以从回答的方式来说,笔者更喜欢讯飞星火V3.5和GPT-4,而文心一言有点啰嗦了。
数学能力
题目:河上有抛物线型拱桥,当水面距拱顶5米时,水面宽度为8米,一小船宽4米,高2米,载货后船露出水面的部分高0.75米,问水面上涨到与抛物线拱顶距多少时,小船开始不能通行?
讯飞星火V3.5

GPT-4

文心一言

单纯的从答案上对比,讯飞星火V3.5和GPT-4(四分之五就不能换算一下么?)的答案均正确,而文心一言的答案是错误的,虽然它的讲解是最详细的,但是数学毕竟需要的是严谨。不过在给学生讲题的过程中将你的逻辑思维传递给学生时,要求是连贯性,能够引导学生学会这道题。所以从这个方面来说,讯飞星火V3.5相比GPT-4显然更胜一筹, 能够一步步通过引导思维来分析题,解答题,最终呈现正确的结果。
办公支持
现如今越来越多的行业开始对接大模型,其目的就是提供更加高效的生产力。所以在办公支持的测试中,我们加入了PPT制作、代码、文案编辑等几个测试。
首先对于很多写代码的程序员,很多都开始使用AI大模型来辅助完善代码工作,这也是大模型应用落地非常广的使用场景。笔者分别向讯飞星火V3.5、GPT-4、文心一言提出展示一个网站的CSS和JavaScript中的粘性标题的代码片段。结果如下:
讯飞星火V3.5
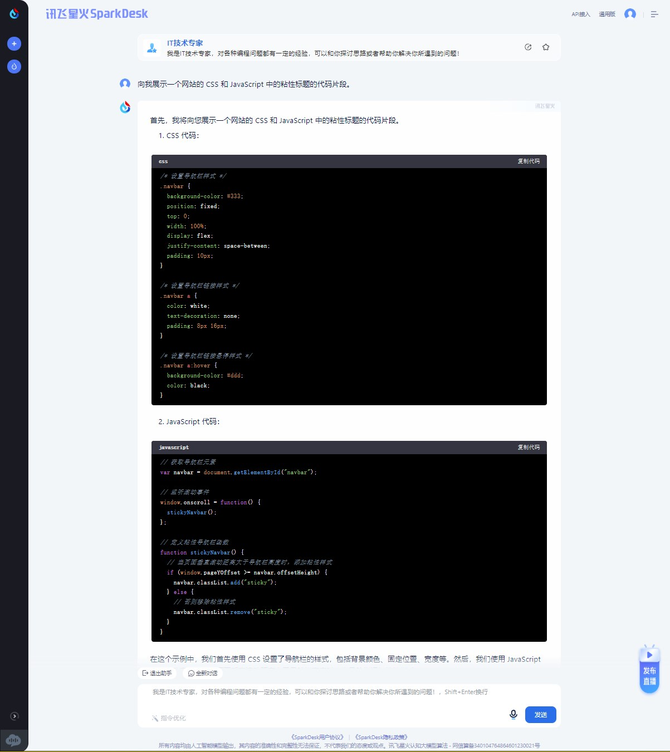
GPT-4
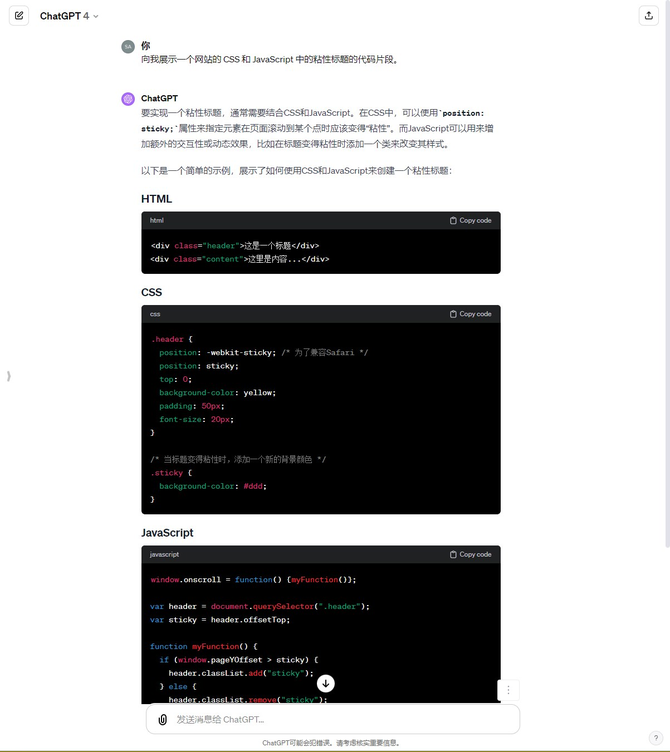
文心一言
从反馈的代码来看,三个大模型对代码的编写都是很在行的,不过讯飞星火V3.5给出的代码格式是最标准的,输出的内容更加丰富,考虑的情况最多,并且格式简洁清爽。而文心一言除了内容丰富外,还增加了重点代码的备注说明,这个能够给初学者提供不小的帮助,是非常人性化的。
另外,在作文水平方面,也是展示大模型对语言组织、文采方面的能力。笔者分别让三个大模型写一篇关于春节的作文,看看讯飞星火V3.5、GPT-4、文心一言谁更出色。
讯飞星火V3.5
GPT-4

文心一言
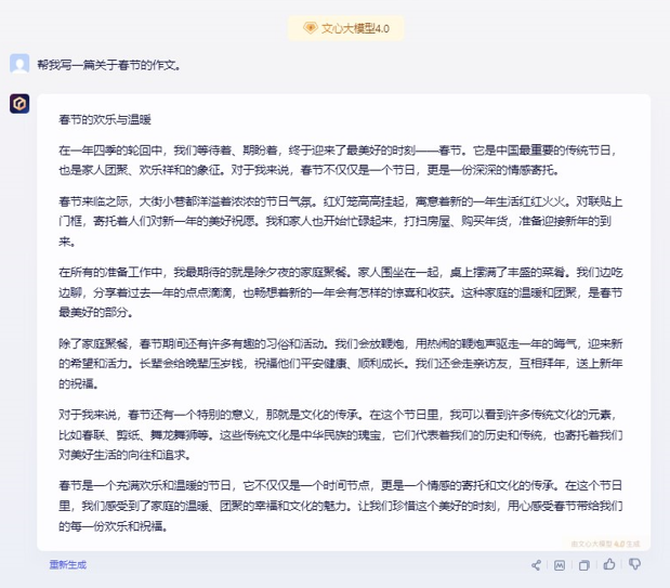
从导出的结果看,GPT-4似乎对中国的作文还有比较深的误解,整个格式均不符合我们作文的方式。讯飞星火V3.5和文心一言比起来,讯飞星火V3.5的作文内容更加的丰富,文采更加优秀,应该更能打动阅卷老师。
多模态能力
通过文字需求生成图片是很多做视觉创意、设计师的工作,也是大模型多模态的基础能力。首先笔者让讯飞星火V3.5、GPT-4和文心一言就“独在异乡为异客,每逢佳节倍思亲。遥知兄弟登高处,遍插茱萸少一人”分别做了一幅画。
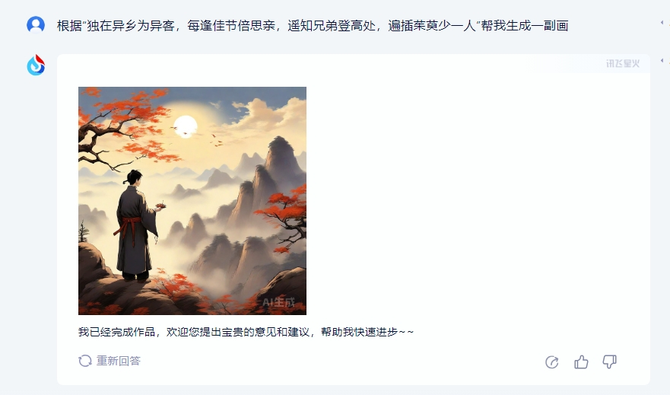
讯飞星火V3.5很快就生成了一副作品,登高望远,整个画面层次感很强,基本符合了诗中的含义。

而GPT-4显示将整首诗的含义进行了解析,画面风格也更加符合诗中有些凄凉的情景,包括手中的茱萸,细节感表现要比讯飞星火V3.5强不少,画面质感也十分不错。
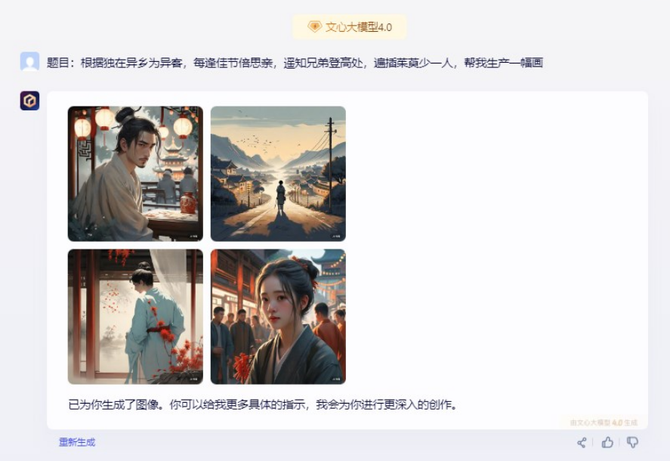
文心一言直接生成了四幅作品,可选余地倒是挺多。不过对整首诗的含义理解就没有那么深刻,仅有一张图将登高望远那种凄凉的感觉展现了出来,同样也是没有GPT-4那么细致。
接下来又要求它们分别展现一艘豪华游轮停泊在城市港口,时间为黄昏,远处有城市,看看三个大模型的表现。

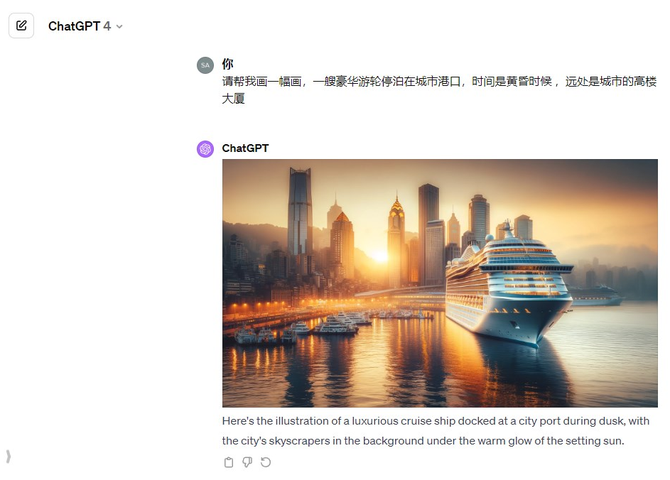
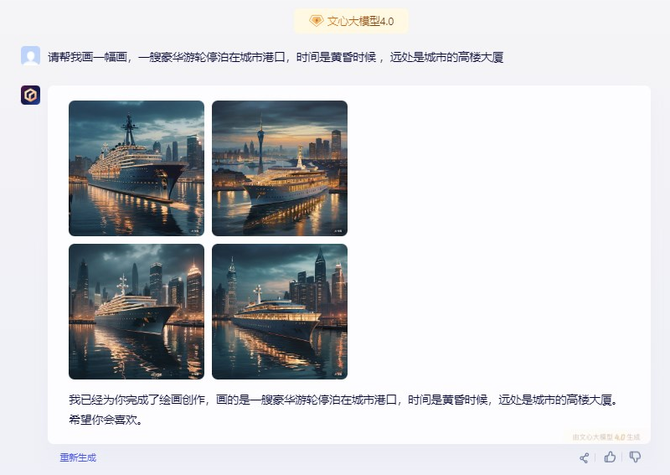
三个大模型所展示的画均符合题目要求,不过仔细看文心一言和GPT-4生成的图片立体感更强烈一些,更有视觉冲击感。文心一言同样还是一次性生成了四张图片,给用户更多的选择空间。而表现最 好的是GPT-4,图片内容非常丰富,展现了太阳即将落下的夕阳,港口密密麻麻的船只,包括城市高楼外观多样性的渲染也都非常清晰,可以说是毫无悬念的胜出。
接下来再试试图生文的能力。

讯飞星火V3.5的图片识别能力还是非常强的,这个三室两厅的平面图分析的十分到位,并每个房间的位置和东西摆放介绍的很清楚,没有明显的错误出现。

而GPT-4对户型的理解完全的错误了,比如它可能将书房看成了入户走廊,餐厅的旁边其实是卫生间,它误认为是厨房。另外GPT-4可能想尽量多体现一些细节,像餐厅里的椅子是六把,它识别成了四把等等。
所以总体上来说,在多模态能力方面,讯飞星火V3.5和GPT-4基本是不分伯仲,两者实际使用体验都非常不错。
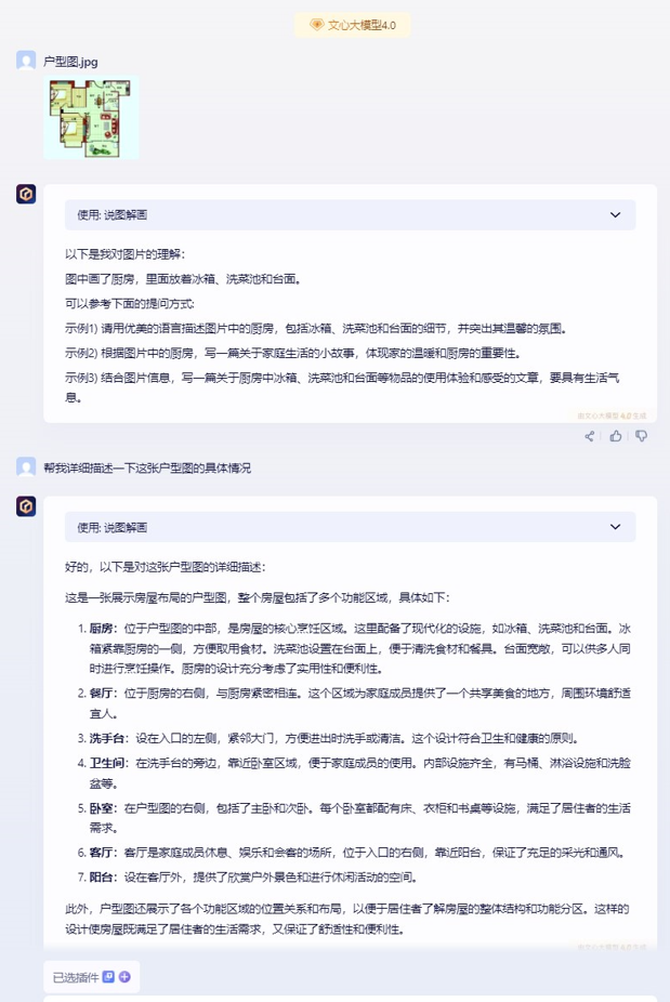
再看看文心一言在图生文方面就是比较欠缺的了,整个房间方位并没有按照图片所示,更像是识别了一张户型图,然后将一些户型图基本信息进行了填充,与图片完全不匹配,
全语音交互
最后笔者也跟发布会一样,与讯飞星火V3.5唠了唠嗑,体验一下本次大模型其中的亮点全语音交互。和我们理解的一条一条的交互方式不同,讯飞星火V3.5更像是在和闺蜜聊天,下面是测试的视频。
笔者分别对讯飞星火V3.5和GPT-4唠了一样的嗑,整体语音识别速度明显感觉出讯飞星火V3.5更加的快捷。同时在语音识别准确率和热点认知上,讯飞星火V3.5也更加准确,明白了用户想去哈尔滨玩的想法,并给出具体建议。
而GPT-4则将“尔滨”的昵称给识别成“耳冰”,解释成耳朵按摩和耳部疗法,虽然也是一种放松方式 ,但完全不是用户想要的答案。
通过对比综合来说,全新发布的讯飞星火V3.5的综合实力又提升了一大步,并且在很多方面已经赶上,甚至超越了GPT-4的表现,尤其是在逻辑推理、数学能力、语音交互这几个方面,更加符合中国人的使用习惯。
不过在文生图这个环节中,讯飞星火V3.5还是有很大提升空间的,比如遍插茱萸少一人这句诗就没能很好的展现在图片中,而GPT-4还是能比较抓住里面的细节,展现给用户。另外文心一言在文生图方面同样表现要优于讯飞星火V3.5,画面真实感更强,更符合用户的需求。
AI大模型可以说是为了人工智能最坚实的基础,只有把地基搭好,才能实现未来在人工智能上面的弯道超车。我们也相信在2024年,讯飞星火有实力赶上GPT-4的发展进程,向世界展示真正的中国实力。

